Pour étudier ou décrire un phénomène statistique, il est dans l’ordre des choses de penser que la prise en compte d’un nombre important de variable améliorerait ou apporterait plus d’information à la compréhension du dit phénomène. Malheureusement, cette logique qui consiste à prendre en compte un nombre important de variables pour gagner en information remet en cause la significativité de cette dernière. C’est l’un des aspects de ce que nous appelons la malédiction de la dimensionnalité ou The curse of dimensionality (moins effrayant en anglais). En effet, plus on n’a de variables ou de dimensions, plus on a besoin d’un échantillon de taille plus importante pour assurer la pertinence ou la significativité de l’information que l’on peut lire des données.
Pour venir about de ce fléau qui mine l’analyse du Big Data, nous pouvons opter pour une réduction du dimensions ce qui implique une perte d’informations mais, perte maîtrisée car nous pouvons alors décider de la quantité d’informations que nous voulons conserver des données originales et donc améliorer la significativité de nos conclusions. La méthode qui permet de réaliser une telle prouesse, Analyse en Composant Principal (ou ACP seulement pour les intimes),a été proposée par Karl Pearson dès 1901 .
Sommaire
Les caractéristiques des composants principaux
Définition
Au delà de la simple réduction de dimension, l’ACP est une méthode visant à synthétiser l’information contenue dans l’ensemble des variables. En fait, elle appartient à un ensemble d’algorithmes de l’apprentissage machine ou machine learning dits non supervisés car ne nécessitant pas de variable dépendante. Elle tire avantage de la variance des variables plus précisément de la corrélation entre elles en éliminant la redondance de l’information contenue dans les variables. Il faut faire attention à ce niveau, l’ACP ne permet pas d’éliminer des variables ! Elle opère à travers un procédé mathématique qui transforme un nombre important de variables qui sont probablement corrélées en un nombre inférieur de variables non corrélées appelées Composant Principal, du fait de leur caractère à absorber le maximum d’information ou de variance dans les variables de départ.
Concrètement, pour  dimensions ou variables, nous avons composants principaux obéissant au principes suivants :
dimensions ou variables, nous avons composants principaux obéissant au principes suivants :
- – Le premier composant principal, est une combinaison linéaire des variables originales, qui maximise la variance dans les données. Géométriquement parlant, ce dernier détermine le sens de variation maximale dans les données. En bref, c’est le composant principal qui absorbe le maximum d’information.
- – Le second composant principal est également une combinaison linéaire des variables originales, qui maximise la variance avec la condition de non-corrélation avec le précédent composant principal.
- – Le reste des composants, obéit à la règle du second composant principal.
Formalisation
Considérons  , la matrice des données numériques de dimension
, la matrice des données numériques de dimension  , de moyenne
, de moyenne  et de variance ou covariance
et de variance ou covariance  , dans laquelle, chaque individu
, dans laquelle, chaque individu  est décrit par les variables numériques
est décrit par les variables numériques  . on appelle composant principal
. on appelle composant principal  , la combinaison linéaire des variables qui s’exprime comme ceci :
, la combinaison linéaire des variables qui s’exprime comme ceci :
![\[\begin{split} Z_i&=W_{i1}X_1+W_{i2}X_2+W_{i3}X_3+\dots +W_{ip}X_p \\ Z_i &= W_{i}^\top X \text{, avec comme variance} \\ \sigma^{2}(z)_i=W_{i}^\top \Sigma W_i \end{split}\]](https://www.ephiquant.com/wp-content/ql-cache/quicklatex.com-53d760665c715b82dcdbfc1bec4df222_l3.png "Rendered by QuickLaTeX.com")
où  est un vecteur de
est un vecteur de  constante.
constante.
Nous devons comme mentionner précédemment trouver et en suite , telle que la variance  soit maximale avec
soit maximale avec  ou
ou  (en fait, on introduit cette contrainte pour éviter que
(en fait, on introduit cette contrainte pour éviter que  ).
).
- – Pour le premier composant principal
 , nous avons le programme suivant à résoudre :
, nous avons le programme suivant à résoudre :
![\[ \begin{cases}\begin{aligned} \text{Max} & & \sigma^{2}(z)_1&=W_{1}^\top \Sigma W_1\\ \text{sc. de} & & W_{1}^\top W_1&=1 \end{aligned} \end{cases} \]](https://www.ephiquant.com/wp-content/ql-cache/quicklatex.com-2f05075a5aabf3ea83e353853030089e_l3.png "Rendered by QuickLaTeX.com")
En utilisant le multiplicateur de Lagrange on obtient que :
(1)

- – Pour le second composant principal
 , nous aurons à résoudre :
, nous aurons à résoudre :
![\[ \begin{cases}\begin{aligned} \text{Max} & & \sigma^{2}(z)_2&=W_{2}^\top \Sigma W_2\\ \text{sc. de} & & W_{2}^\top W_2&=1 \\ & & W_{2}^\top W_1&=0\end{aligned} \end{cases} \]](https://www.ephiquant.com/wp-content/ql-cache/quicklatex.com-36b5f8e8b8a5027d27db2a4b975e377c_l3.png "Rendered by QuickLaTeX.com")
En utilisant le multiplicateur de Lagrange on obtient que :
(2)

- – Pour le reste des composants principaux, on utilise le programme du second composant en incrémentant pour
 allant de 3 à composant principal. on obtiendra de manière générale que :
allant de 3 à composant principal. on obtiendra de manière générale que :
(3)

La première remarque que l’on fait c’est que pour que les équations (1), (2) soient possibles et de façon générale l’équation (3) , il faudrait que les vecteurs et les valeurs  soient respectivement des vecteurs et valeurs propres de . Mieux encore on peut donc conclure que :
soient respectivement des vecteurs et valeurs propres de . Mieux encore on peut donc conclure que :
(4) ![\begin{equation*}\sigma^{2}(z)_i=Var[W_{i}^\top X] = W_{i}^\top\Sigma W_i = \lambda_i\end{equation*}](https://www.ephiquant.com/wp-content/ql-cache/quicklatex.com-43307359e1a5ad73fa15a38d049d2800_l3.png "Rendered by QuickLaTeX.com")
Autrement dit, la variance d’un composant principal est égale à la valeur propre de la matrice de variance – covariance .
 , sont centrées et réduites pour annihiler l’effet de la différence des unités ou des échelles de mesures de chaque variable sur la variance. Cette standardisation n’est pas nécessaire si les variables sont toutes dans la même unité mais il est toujours conseillé de la faire
, sont centrées et réduites pour annihiler l’effet de la différence des unités ou des échelles de mesures de chaque variable sur la variance. Cette standardisation n’est pas nécessaire si les variables sont toutes dans la même unité mais il est toujours conseillé de la faireCritère de rétention d’un composant principal
Une fois, nos composants déterminer, nous devons retenir ceux ayant des variances importantes et ignorer ceux ayant de faibles variances. Pour ce faire on peut se baser sur les critères suivantes( ce ne sont pas des lois) :
- Retenir les
 composants ayant une valeur propre supérieure à 1(Critère de Kaiser – Guttman)
composants ayant une valeur propre supérieure à 1(Critère de Kaiser – Guttman) - Retenir les composants dont les valeurs propres précédent la cassure de la courbe on parle aussi du coude
- Retenir les premiers composants qui expliquent
 de la variance.
de la variance. - Retenir les premiers composants dont la part ou proportion de variance est supérieur à la moyenne(
 % >
% >  %)
%)
Nous allons utiliser les données issues du rapport 2016 de Heritage. Elle contiennent 7 variables économiques de 169 pays. Nous aurons besoin d’installer et d’importer les packages suivants pour l’implémentation de l’ACP :
|
1 2 3 4 5 |
import pandas as pd import numpy as np from matplotlib import pyplot as plt from mpl_toolkits.mplot3d import Axes3D import seaborn as sns |
Chargement et description statistique des données :
Nos données sont stockées sous format .csv, aussi nous allons utiliser la fonction read_csv() de la librairie pandas :
|
1 2 3 4 5 6 |
url = 'https://docs.google.com/spreadsheets/d/1Qk4qNu8dZSBbw_cPgZC0r-jIDt7gLFp0ra0cyoqpCbY/pub?output=csv' db = pd.read_csv(filepath_or_buffer= url, sep=',') db.head() db.tail() db.dtypes # types de variables db.shape |
Ensuite nous allons avec la fonction describe() obtenir une description statistique des données, nous avons les principaux indicateurs de tendance centrale et de dispersion :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
>>> # Renommer les variables >>> db.columns = ['Pays','Region','pop','pib','chomage', ... 'inflation','ide','dette_publik', ... 'corrup_indice'] >>> # visualisation des mesures de statistique descriptive ... db.describe() pop pib chomage inflation ide \ count 169.000000 169.000000 169.000000 169.000000 169.000000 mean 41.968047 638.236864 8.820118 4.419231 7244.549112 std 147.034910 2068.930753 7.209696 6.961893 17993.503001 min 0.300000 1.090000 0.300000 -1.600000 -4956.680000 25% 3.600000 27.130000 4.300000 0.910000 363.270000 50% 9.500000 81.120000 6.900000 2.900000 1200.000000 75% 30.600000 409.330000 10.900000 5.990000 4901.840000 max 1367.800000 17617.320000 60.000000 62.170000 128500.000000 dette_publik corrup_indice count 169.000000 169.000000 mean 50.195799 42.875148 std 34.436074 19.835297 min 0.000000 6.700000 25% 29.800000 28.000000 50% 41.600000 38.000000 75% 65.000000 55.000000 max 246.400000 92.000000 |
Pour la visualisation graphique compte tenu du nombre de variables, les projeter individuellement nous donnerait un travail de longue haleine. Heureusement, avec la fonction PairGrid() de la librairie seaborn nous pouvons faire une analyse graphique des variables prises deux à deux et même visualiser la distribution de ces dernières.
|
1 2 3 4 5 6 7 8 9 |
# log - transfomation et exclusion des NAN logdb = pd.concat([np.log10(db.ix[:,2:9])], axis=1).replace([np.inf, - np.inf], np.nan).dropna() g = sns.PairGrid(logdb) g.map_upper(sns.regplot) g.map_lower(plt.scatter) g.map_diag(plt.hist) plt.show() |
Dans notre cas au vu des caractéristiques des données nous avons d’abord procédé à une log-transformation des données(à des fins de visualisations compte tenu de la disparité des échelles des données intra-et inter- variables) ensuite nous avons opté pour des nuages de points et des histogrammes :
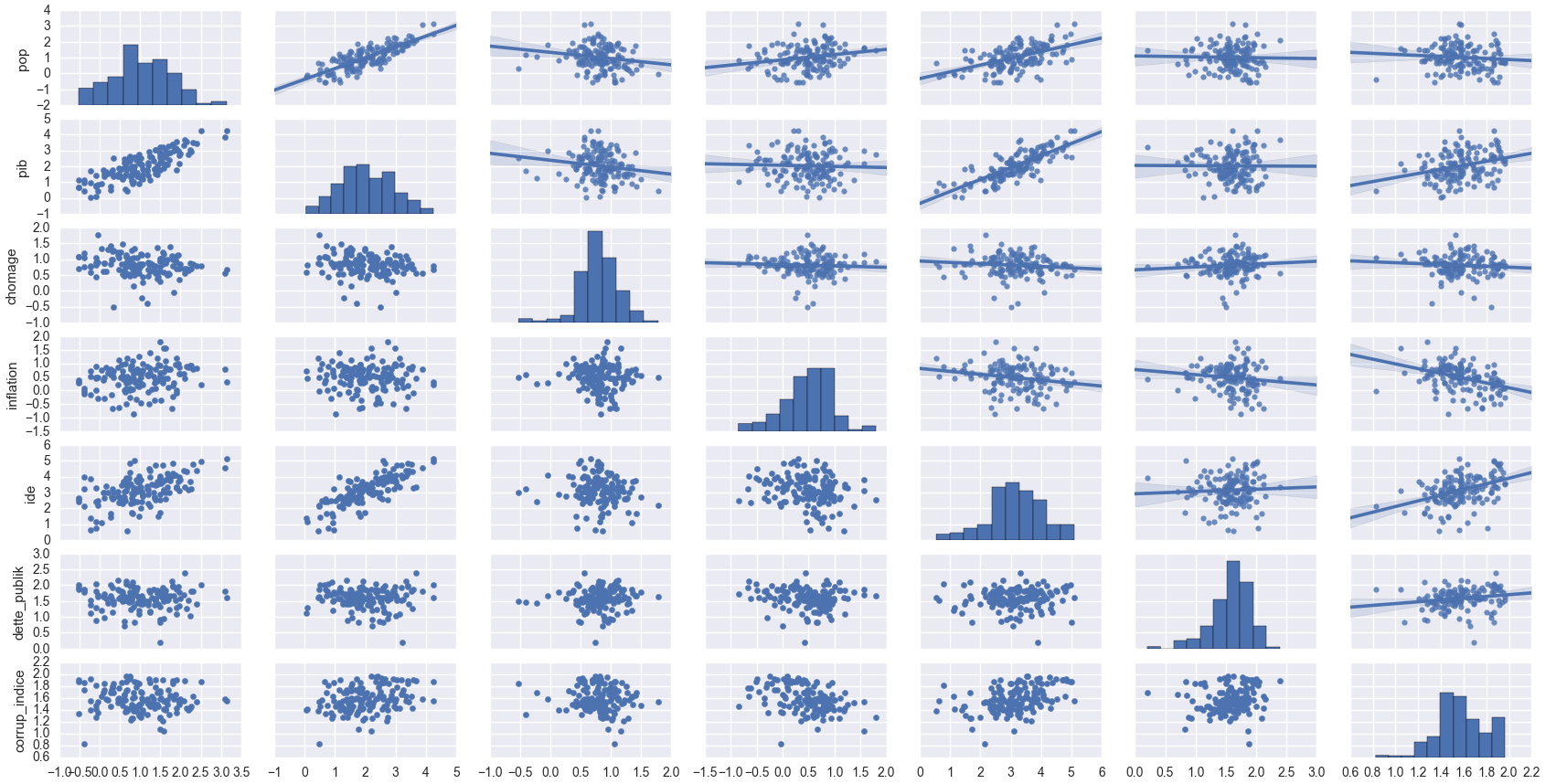
Vous pourriez naturellement remplacer les données np.nan , par les valeurs minimales ou tout autre mode de traitement de ce type de données. Nous avons choisi de les exclure. Les coefficients de corrélations s’obtiennent comme ceci :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
>>> db.ix[:,2:9].corr().round(2) pop pib chomage inflation ide dette_publik \ pop 1.00 0.77 -0.11 0.03 0.55 0.03 pib 0.77 1.00 -0.10 -0.02 0.71 0.17 chomage -0.11 -0.10 1.00 -0.05 -0.13 0.15 inflation 0.03 -0.02 -0.05 1.00 -0.08 -0.06 ide 0.55 0.71 -0.13 -0.08 1.00 0.08 dette_publik 0.03 0.17 0.15 -0.06 0.08 1.00 corrup_indice -0.04 0.14 -0.05 -0.31 0.33 0.27 corrup_indice pop -0.04 pib 0.14 chomage -0.05 inflation -0.31 ide 0.33 dette_publik 0.27 corrup_indice 1.00 |
Standardisation des données
Comme mentionner précédemment, il est impératif de centrer et réduire les variables sur lesquelles nous allons procéder à une ACP :
|
1 2 3 4 |
S = np.diag(1/db.ix[:,2:9].std()) mu = np.matrix(db.ix[:,2:9].mean()) U = np.matrix([np.ones(db.ix[:,2:9].shape[0])]) X = pd.DataFrame((db.ix[:,2:9] - U.T.dot(mu)).dot(S).values,columns = db.columns[2:9]) |
Pour centrer et réduire, on peut utiliser des opérations matricielles comme ci-dessous où recourir à la fonction StandardScaler().fit_transform(db.ix[:,2:9]) , précédée du chargement suivant from sklearn.preprocessing import StandardScaler
Détermination des valeurs et vecteurs propres
La fonction np.linalg.eig(), permet d’obtenir et les valeurs et les vecteurs propres, malheureusement ces derniers ne sont souvent dans un ordre souhaité :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
>>> Var_X = X.cov() # obtenir la matrice variance covariance >>> val_propres,vec_propres = np.linalg.eig(Var_X) >>> ordre = val_propres.argsort()[::-1] >>> val_propres = val_propres[ordre] >>> vec_propres = vec_propres[:,ordre] >>> val_propres array([ 2.47139835, 1.4481121 , 1.07579038, 0.87588825, 0.63277798, 0.32250087, 0.17353206]) >>> vec_propres array([[ 0.51905632, 0.2882542 , -0.13257068, 0.17093657, 0.21782766, -0.53914789, -0.51241236], [ 0.58653886, 0.11708648, -0.12470379, 0.05594056, 0.06492594, -0.04484539, 0.78572009], [-0.11658595, -0.22448201, -0.7330986 , 0.51089215, -0.36917483, -0.03559414, -0.00376848], [-0.07545644, 0.52547596, -0.32138423, -0.60612799, -0.48618549, -0.10539125, 0.00432858], [ 0.54983653, -0.02099039, 0.0833643 , 0.02866106, -0.34878119, 0.67811177, -0.32860957], [ 0.14086425, -0.44646528, -0.49822193, -0.53615785, 0.46196584, 0.14032646, -0.10968929], [ 0.21237656, -0.613931 , 0.26641679, -0.22574925, -0.4905187 , -0.46411971, 0.00534719]]) |
Notez ici que nous aurions pu procéder à la décomposition avec la fonction np.linalg.svd(Var_X) . Par ailleurs, nous allons calculer ci-dessous l’écart- type, la part ou proportion de variance de chaque composant ainsi que le cumul de variance expliquée afin de mieux visualiser la contribution de chaque composants principal :
|
1 2 3 4 5 6 7 8 |
row = ["Comp." + str(i+1) for i in range(7)] col = ["Std deviation","Prop.of Variance(%)","Cumulative Prop.(%)"] tot = sum(val_propres) res_1 = pd.DataFrame([[i**0.5,np.round(i*100 /tot,2),np.round(j*100/tot,2)] for i,j in zip(val_propres,np.cumsum(val_propres))], columns= col,index = row) res_2 = pd.DataFrame(vec_propres,columns = row, index = db.columns[2:9]) |
Choix des composants principaux :
D’une part dans l’objet res_1 , nous pouvons lire que le premier composant principal capture à lui seul 35% de l’information ou variance et le deuxième composant 20%…etc
|
1 2 3 4 5 6 7 8 9 |
>>> res_1 Std deviation Prop.of Variance(%) Cumulative Prop.(%) Comp.1 1.572068 35.31 35.31 Comp.2 1.203375 20.69 55.99 Comp.3 1.037203 15.37 71.36 Comp.4 0.935889 12.51 83.87 Comp.5 0.795473 9.04 92.91 Comp.6 0.567892 4.61 97.52 Comp.7 0.416572 2.48 100.00 |
Aussi, le cumul des proportions nous montre que les deux premiers composants n’expliquent que 55% de la variance ce que nous jugeons insuffisant donc nous allons retenir les trois premiers composants qui capturent 71%.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
plt.clf() plt.subplot(211) plt.axis([0.5,7.5,0,105]) plt.bar(range(1,8), res_1.ix[:,1], alpha=0.5, align='center', label="Proportion of Variance(%)") plt.step(range(1,8),res_1.ix[:,2], where='mid', label="Cumulative Proportion(%)") plt.ylabel("Variance expliquée") plt.xlabel("Composant principal") plt.legend(loc='best') plt.subplot(212) plt.axis([0.5,7.5,0,40]) plt.plot(range(1,8),res_1.ix[:,1], linestyle='--', marker='o', color='black') plt.ylabel("Valeur propres") plt.xlabel("Composant principal") plt.title("Scree plot") plt.tight_layout() plot.show() |
Ce tableau peut être visualiser graphiquement, on lit sur le deuxième graphique, le Scree plot notamment que le point de cassure ou le coude, se trouve au niveau du troisième composant et compte tenu de l’importance de l’information contenue dans ce troisième composant soit 15%(> à la moyenne (1/7 ~ 14%)).

D’autres part, dans l’objet res_2 , nous avons les vecteurs propres ou la contribution de chaque variable à chaque composant. Et comme décidé ci-dessus, nous allons extraire seulement les 3 premiers composants ainsi que leur vecteur.
Réduction de dimension et projection graphique
Nous arrivons donc à la fin de cet article, nous allons passer d’un espace à 7 dimensions(ce qui était impossible à projeter graphiquement) à un sous espace de 3 dimensions(le maximum qu’on peut faire graphiquement parlant), ce qui va nous conduire à réaliser une projection en 3D à la place de l’habituel biplot(dans le cas de deux composants principaux).
|
1 2 3 4 5 6 7 8 9 |
>>> W = res_2.ix[:,0:3] # extration des vecteurs propres >>> Z = pd.concat([db.ix[:,0:2],X.dot(W)],axis = 1) >>> Z.head() Pays Region Comp.1 Comp.2 Comp.3 0 Afghanistan Asia-Pacific -0.936261 1.480023 0.188455 1 Albania Europe -0.599799 -0.525962 -1.024873 2 Algeria Middle East / North Africa -0.449635 0.610582 0.488135 3 Angola Sub-Saharan Africa -0.837208 1.129783 -0.079627 4 Argentina South and Central America / Caribbean -0.382677 2.837451 -1.586402 |
Pour finir, dans le code ci-dessus, nous avons calculer les  qui vont servir à réaliser le graphique ci-dessous :
qui vont servir à réaliser le graphique ci-dessous :

On peut voir sur le graphique les USA, la Chine et l’inde se distinguer du lot sur l’axe du CP1,ce dernier met avant notamment des pays à Population importante mais aussi à fort PIB, l’axe du CP2 des pays à fort taux corruption,d’inflation …etc vous maintenant !
|
1 2 3 |
from sklearn.decomposition import PCA as princomp cpa = princomp(n_components=3) Z = cpa.fit_transform(X) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
colour =('orange', 'white', 'black','violet','green','yellow') region = tuple(Z.ix[:,1].unique()) plt.close() fig= plt.figure(figsize=(20,20)) ax = Axes3D(fig) for i, j in zip(region,colour): ax.scatter(Z.ix[Z.Region==i, 2], Z.ix[Z.Region==i, 3], Z._ix[Z.Region==i,4], label=i, c=j,s=30) ax.plot([0], [0], [0], 'o', markersize=12, color='red') for s,lab in zip(vec_propres,res_2.index): ax.plot([0, s[0]], [0, s[1]], [0, s[2]], color='red', lw=2) ax.text(s[0], s[1], s[2],lab,size = 7,color='red') for n,t in zip(Z.index,Z._ix[:,0]): ax.text(Z.ix[n, 2], Z.ix[n, 3], Z.ix[n, 4],t,size = 5,color = 'darkblue') ax.set_xlabel('Composant Principal 1(~ 35%)') ax.set_ylabel('Composant Principal 2(~ 21%)') ax.set_zlabel('Composant Principal 3(~ 15%)') plt.show() |







